Het probleem met tags in programmatische SEO
Programmatische SEO maakt aparte pagina’s voor zoektermen: onderwerppagina’s die relevante content bundelen. De theorie is simpel: bepaal 27 kernonderwerpen (React, AI, Backend), en laat automatisch alle artikelen, cases en teamprofielen op de juiste pagina verschijnen.
De praktijk werkt anders. Contentteams schrijven niet “React”, ze schrijven “React development”, “React consulting”, “React architecture”. Exacte matching faalt. Onderwerppagina’s blijven leeg terwijl er wel relevante content is.
Handmatig beheer schaalt niet. “AI implementation” → “AI” koppelen werkt tot je 140 verschillende tags hebt. Dan besteedt iemand 8 uur per maand aan het bijwerken van een mappingbestand. Eén typfout en alles breekt.
We wilden weten: kunnen we betekenismatching gebruiken in plaats van exacte matching?
Anders naar het probleem kijken
De doorbraak: stop met denken in exacte matching. Zie het als een clustering probleem waarbij vergelijkbare termen vanzelf bij elkaar komen.
Wat we hebben:
- 27 kernonderwerpen (React, AI, Backend, etc.): de vaste categorieën
- 140 tag variaties: alle benamingen die je team gebruikt
- Doel: Elke variatie automatisch koppelen aan het meest passende onderwerp
- Regel: Past iets nergens bij? Laat het dan los
Door tags te zien als clustering in plaats van matching, automatiseren we wat eerst uren handwerk kostte.
Hoe het werkt
De aanpak heeft drie stappen:
Stap 1: Van tekst naar betekenis
Gebruik OpenAI embeddings om elke tag en categorie om te zetten in een numerieke representatie. Vergelijkbare betekenissen krijgen vergelijkbare getallen, dus “AI strategie” ligt wiskundig dicht bij “AI”, ook al verschillen de woorden.
Zie het als GPS-coördinaten voor betekenissen. Verwante termen worden neighbors.
Stap 2: Bouw een stamboom van verwante termen
Gebruik hierarchical clustering om vergelijkbare termen te groeperen. Dit bouwt een boom die laat zien welke termen het meest verwant zijn: startend met losse termen onderaan, steeds verder samenvoegend, tot alles bovenaan verbonden is.
Stap 3: Vind de juiste afkapgrens
Snijd de boom af op een hoogte waarbij elke groep maximaal één kernonderwerp bevat:
- Eén kernonderwerp per groep → Alle tags in die groep horen daarbij
- Geen kernonderwerp → Dit zijn outliers die nergens passen
- Meerdere kernonderwerpen → Snijd hoger af om ze te scheiden
Zo wordt elke tag aan precies één categorie gekoppeld, en items die nergens bij horen worden gemarkeerd.
De dendrogramvisualisatie
Zo ziet de clustering eruit voor onze data:
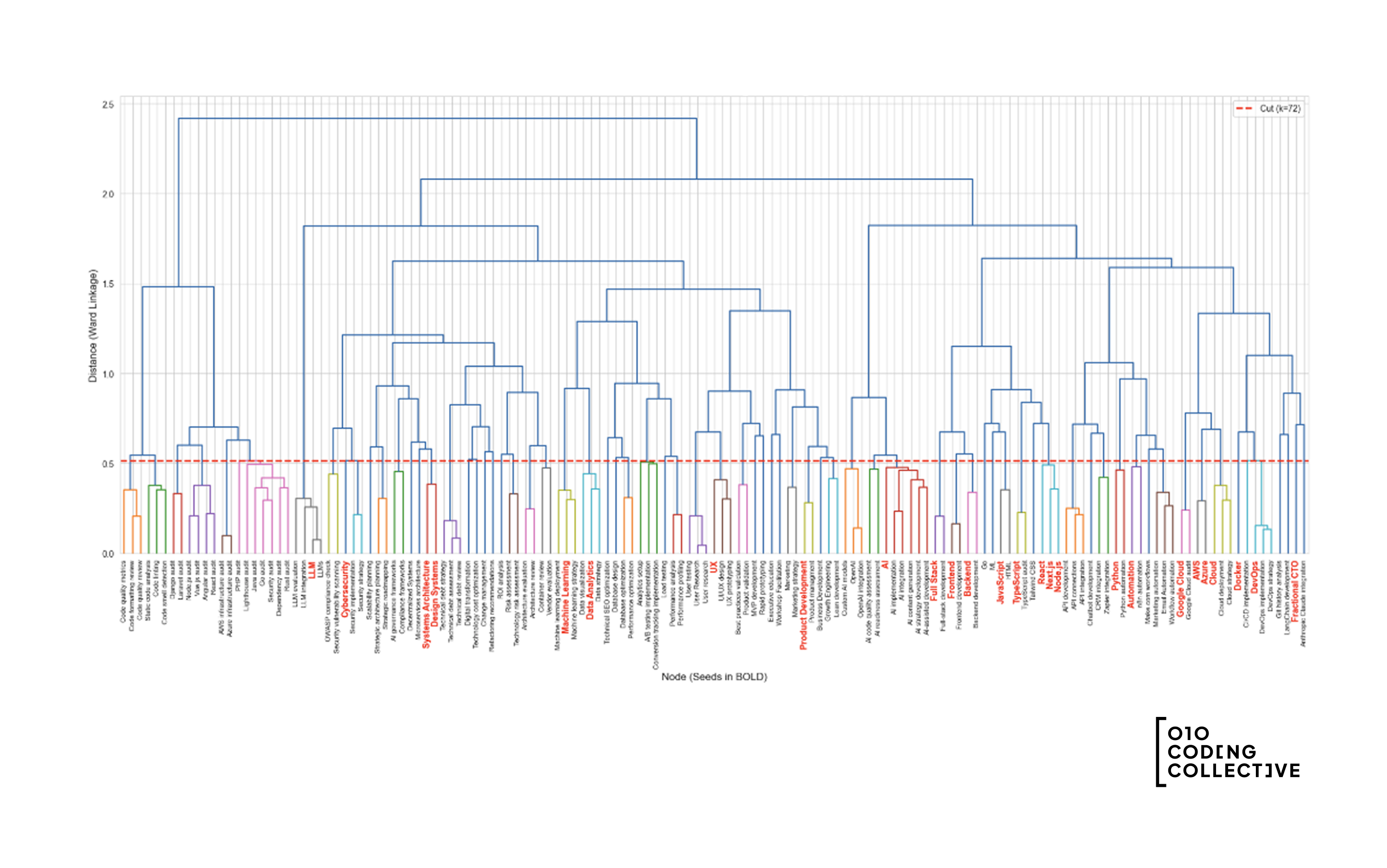
Hoe dit te lezen:
- X-as: Elk blad is een tag of onderwerp. Kernonderwerpen zijn vetgedrukt.
- Y-as: Afstand (hoe verschillend items zijn bij samenvoeging)
- Takken: Laten zien welke items samengevoegd werden
- De afkapgrens: Waar we de boom scheiden in groepen
Tags die onder de afkapgrens verbonden zijn, horen bij dezelfde groep en worden allemaal gekoppeld aan het kernonderwerp van die groep.
Resultaten
We testten dit op echte data: 27 kernonderwerpen en 140 tags.
Sterke matches: 128 van de 140 tags werden netjes gekoppeld. Het algoritme draaide in ongeveer 30 seconden.
Hiaten vinden: 12 tags pasten nergens: “Blockchain,” “Rust,” “Flutter.” Geen fouten. Ze laten zien over welke onderwerpen je schrijft maar waar je geen aparte pagina’s voor hebt. Automatisch contentstrategie-inzicht.
Consistent: Draai het meerdere keren, krijg steeds hetzelfde resultaat. Daardoor geschikt voor automatisering.
Waar dit nog meer werkt
Dezelfde aanpak werkt overal waar je wilde benamingen wilt bundelen in vaste categorieën:
Webshops: “Sneakers,” “trainers,” “hardloopschoenen” worden allemaal “Atletische schoenen.”
Vacatureplatforms: “React.js,” “ReactJS,” “React developer” worden allemaal “React.”
Kennisbanken: Koppel vragen aan het juiste helpartikel, ook als ze het anders formuleren.
Content management: Houd tags consistent over schrijvers heen, zonder handwerk.
Het patroon: wilde benamingen bundelen in vaste categorieën door betekenis te begrijpen, niet alleen exacte matching.
Implementatie
We hebben de implementatie open-sourced als Google Colab notebook. Het notebook neemt:
- Een lijst kernonderwerpen (jouw vaste categorieën)
- Een lijst tags (de variaties die je wilt bundelen)
Het geeft terug:
- Koppelingen van tags naar categorieën met betrouwbaarheidsscores
- Dendrogram visualisatie die de hiërarchie laat zien
- Lijst outliers (losse tags)
- Exporteerbare JSON en CSV bestanden
Nodig: OpenAI API key voor embeddings. Het notebook bevat voorbeelddata om mee te testen.
Het belangrijkste inzicht: Anders naar het probleem kijken maakte de oplossing duidelijk. Zodra we stopten met denken “hoe matchen we woorden?” en begonnen met “hoe clusteren we op betekenis?”, werd de weg helder.
Heb je vergelijkbare vraagstukken rond tags en taxonomie? Neem contact op.
