The taxonomy problem in programmatic SEO
Programmatic SEO creates dedicated pages for target keywords: topic pages that aggregate related content. The theory is simple: define 27 core topics (React, AI, Backend), then automatically surface all related articles, case studies, and team profiles on each page.
The practice breaks immediately. Content teams don’t write “React”, they write “React development”, “React consulting”, “React architecture”. Your string matching fails. Topic pages sit empty while relevant content exists.
Manual maintenance doesn’t scale. Mapping “AI implementation” → “AI” works until you have 140 unique technology mentions. Then someone spends 8 hours monthly updating a mapping file. One typo breaks everything.
We wanted to understand: can semantic similarity replace string matching for taxonomy normalization?
Reframing the problem
The breakthrough: stop thinking about exact text matches. Instead, treat this as a clustering problem where similar terms naturally group together.
What we’re working with:
- 27 target topics (React, AI, Backend, etc.): your canonical categories
- 140 content tags: all the variations your team actually uses
- Goal: Automatically match each variation to its closest target topic
- Rule: If something doesn’t clearly fit anywhere, leave it unmapped
By reframing taxonomy maintenance as a grouping problem instead of a matching problem, we can automate what previously required hours of manual work.
How it works
The approach has three steps:
Step 1: Convert text to meaning
Use OpenAI embeddings to convert each tag and category into a numerical representation. Similar meanings get similar numbers, so “AI strategy” ends up mathematically close to “AI”, even though the words differ.
Think of it like giving each term GPS coordinates in “meaning space.” Related terms end up as neighbors.
Step 2: Build a family tree of similar terms
Use hierarchical clustering (Ward’s method) to group similar terms together. This builds a tree showing which terms are most related: starting with individual terms at the bottom, gradually merging similar ones, until everything connects at the top.
Step 3: Find the right cut point
Cut the tree at a height where each resulting group has at most one target category:
- One target in a group → All tags in that group belong to that target
- No target in a group → These are outliers that don’t fit anywhere
- Multiple targets → Cut higher up to separate them
This ensures every tag gets assigned to exactly one category, and items that don’t clearly belong anywhere get flagged.
The dendrogram visualization
Here’s what the clustering looks like for our data:
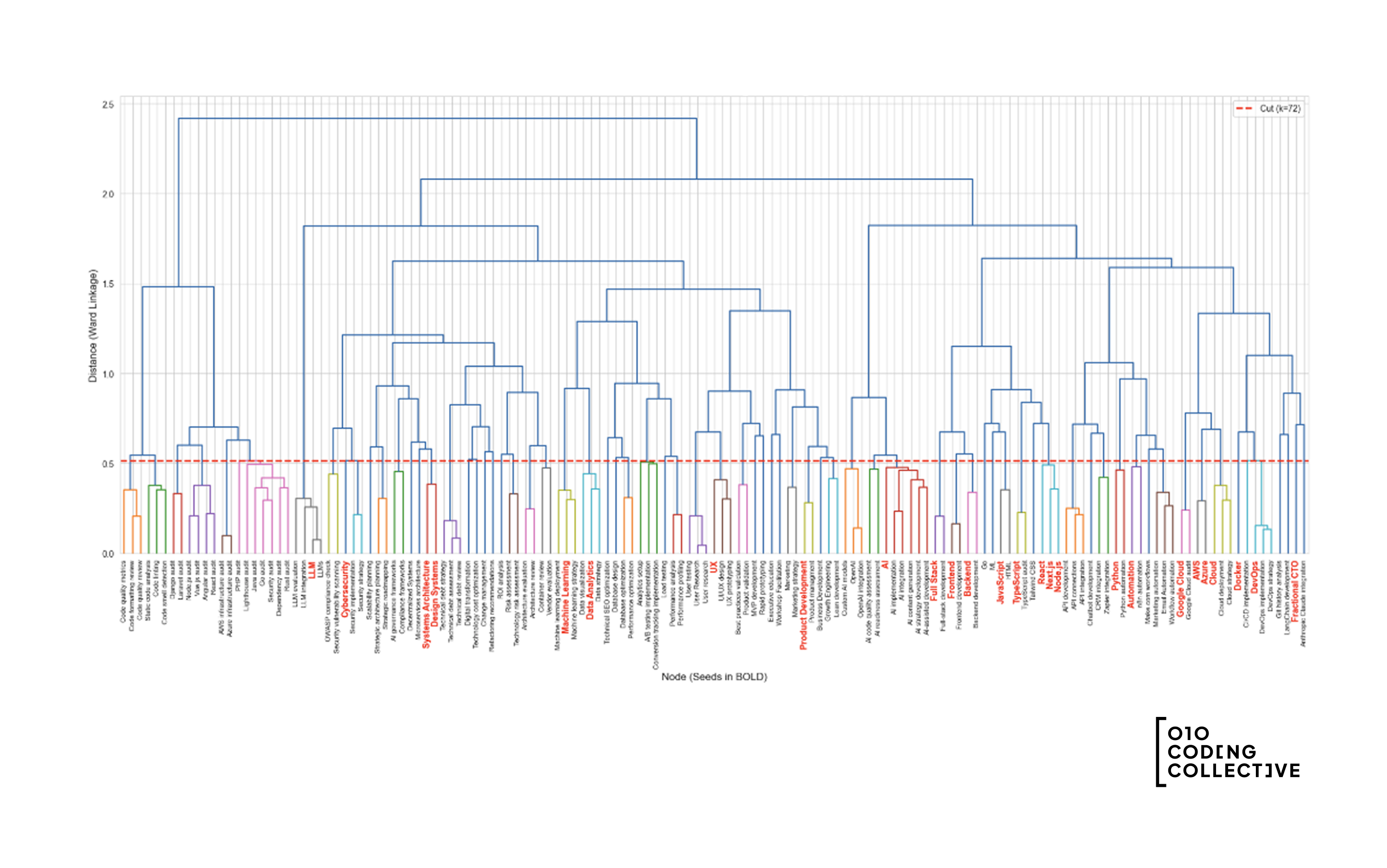
How to read this:
- X-axis: Each leaf is a tag or topic. Target topics are in bold.
- Y-axis: Distance (how different items are when merged)
- Branches: Show which items grouped together
- The cut line: Where we separated the tree into groups
Tags connected below the cut line belong to the same group, all mapping to that group’s target topic.
Results
We tested this on real data: 27 target categories and 140 content tags.
Strong matches: 128 out of 140 tags mapped cleanly to a target. The algorithm ran in about 30 seconds.
Gap detection: 12 tags didn’t fit anywhere: “Blockchain,” “Rust,” “Flutter.” These aren’t mistakes. They reveal content topics you’re writing about but don’t have dedicated pages for. Automatic content strategy insights.
Consistent: Run it multiple times, get the same results. This makes it reliable for automation.
Where else this helps
The same approach works anywhere you need to normalize messy human language into clean categories:
E-commerce: “Sneakers,” “trainers,” “running shoes” all map to “Athletic Footwear.”
Job platforms: “React.js,” “ReactJS,” “React developer” all map to “React.”
Knowledge bases: Match user questions to the right help doc, even when they phrase things differently.
Content management: Keep tags consistent across multiple writers without manual cleanup.
The pattern: turning messy human language into organized categories by understanding meaning, not just matching words.
Implementation
We’ve open-sourced the implementation as a Google Colab notebook. The notebook accepts:
- A list of target categories (your canonical taxonomy)
- A list of content tags (the variations to normalize)
It outputs:
- Tag-to-category mappings with confidence scores
- Dendrogram visualization showing hierarchical structure
- List of outliers (unmapped tags)
- Exportable JSON and CSV files
Requirements: OpenAI API key for embedding generation. The notebook includes example data for testing.
The key insight: Reframing the problem made the solution obvious. Once we stopped thinking “how do we match strings?” and started thinking “how do we group similar meanings?”, the approach became clear.
If you’re dealing with similar taxonomy challenges, get in touch.
